심층 강화학습 기반 자율 주행 자동차의 램프구간 주행 정책 연구
Copyright Ⓒ 2024 KSAE / 224-03
This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License(http://creativecommons.org/licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium provided the original work is properly cited.
Abstract
As autonomous driving systems attract more attention, it is important to develop a driving strategy on complex road conditions, e.g., on-ramp merging scenarios. Deep Reinforcement Learning (RL) is a promising solution for building an autonomous driving policy because it uses neural networks as functional approximators, enabling autonomous vehicles to adapt to dynamic and unpredictable scenarios. In this study, we aimed to develop RL-based, on-ramp merging strategies that minimize disruption to traffic flow and ensure safe merging. Specifically, we designed a Partially Observable Markov Decision Process (POMDP), and then trained the driving strategy by using three deep RL algorithms. Simulation results demonstrated that the RL-based driving strategy could outperform the control-theoretic strategy, thus improving the traffic flow in the ramp lane by 4.52% and the main lane by 2.13%.
Keywords:
Autonomous driving system, Deep reinforcement learning, Partially observable Markov decision process, On-ramp merge, Decision-making키워드:
자율주행 시스템, 심층 강화학습, 부분 관측 가능한 마르코프 의사결정, 램프구간 병합, 판단1. 서 론
최근 인공지능 분야의 빠른 발전과 함께 자율주행 기술에 대한 연구가 다방면에서 진행되고 있다. 실제 최근 조건부 자율주행 기술이 상용화되고 있으며, 운전자의 개입을 요구하지 않는 4단계 이상의 완전 자율주행 시스템 또한 빠른 시일 내에 도입될 것으로 전망되고 있다.1) 하지만, 고속도로 램프구간2)을 위한 자율주행 기술 개발에는 여전히 기술적 완성도의 한계가 존재한다. 램프구간에서의 기술적 어려움은 주행 환경의 변화가 불확실하고 동적이므로 타 도로 구조 대비 보다 유연하며 정밀한 의사결정 능력이 요구되기 때문이라 보고되고 있다.3)
자율 주행 자동차의 의사결정은 자율주행 시스템 구성 요소 중 판단으로 분류되며, 이는 전통적으로 제어이론(Control-theoretic)에 기반하여 수행되어 왔다. 제어이론 기반의 자율주행 정책은 사전 정의된 규칙 내에서 의사결정을 수행하는 방식(Rule-based)을 따르며, 규칙 내 주행 상황에 대해 최적의 의사결정을 수행할 수 있다. 하지만, 사전에 정의되지 않은 예상치 못한 환경에서의 유연한 주행이 어렵다는 한계가 존재한다.4,5) 불규칙한 교통 환경이 조성되는 램프구간에서의 유연하지 못한 주행은 교통 정체의 심화 혹은 충돌 사고로 이어질 수 있기 때문에 보다 유연한 합류 주행 정책을 필요로 한다.
심층 강화학습 기반의 자율주행 시스템은 제어이론 방식의 한계를 개선하기 위한 기술로 고려될 수 있다. 해당 방법에서 자율 주행 자동차는 다양한 교통 환경을 경험하는 과정을 통해 주행 정책을 학습한다. 이때, 심층 강화학습은 심층 신경망을 활용하여 의사결정을 수행하고 온라인 학습 환경에서 다양한 경험을 통해 학습하기 때문에 새로운 환경이나 작업에 대해서도 유연한 의사결정이 가능하다.6-9) 이러한 특성은 불규칙한 도로 환경에 대한 성공적인 의사결정을 가능하게 했으며10), 이를 통해 심층 강화학습 기반 자율주행 정책 연구가 활발히 진행되었다.11-13)
심층 강화학습 기반 자율주행 정책의 주행 특성은 마르코프 의사결정 MDP(Markov Decision Process) 모델의 설계 및 학습 알고리즘에 따라 다르게 나타날 수 있다. 자율 주행 자동차는 MDP에서 정의된 상태에 따라 행동 수행 및 설계된 보상 함수(Reward function)를 기반으로 정책을 개선하기 때문에 성공적인 주행 정책의 학습을 위해서는 MDP의 설계가 매우 중요하다. 또한, 동일한 MDP도 학습 알고리즘에 따라 주행 특성의 차이를 야기할 수 있다.14) 이러한 특성에도 불구하고, 많은 자율주행 연구에서는 단일 알고리즘만을 통해 주행 정책을 학습 및 분석한다.15,16) 알고리즘에 따라 주행 특성이 다르게 학습될 수 있기 때문에 설계된 MDP를 정밀하게 검증하기 위해서는 다양한 강화학습 알고리즘을 통한 분석이 요구되며, 알고리즘에 따른 주행 정책의 변동성이 낮을수록 강건한 MDP로 평가할 수 있다.
본 연구에서는 교통 환경이 동적으로 변화하는 램프구간에서 자율 주행 자동차의 안전하고 효율적인 주행 정책 구축을 목표로 한다. 기존 규칙기반 방식의 한계를 보완하기 위해 심층 강화학습을 위한 POMDP 모델을 제안하며, 정책 학습에는 심층 강화학습 알고리즘인 PPO(Proximal Policy Optimization)17), DDPG(Deep Deterministic Policy Gradient)18), TD3(Twin Delayed DDPG)19)를 사용한다. 이후 각 알고리즘으로 학습된 심층 강화학습 기반의 자율 주행 자동차와 제어이론 기반의 자율 주행 자동차 간 주행 특성과 성능을 비교 분석한다.
본 논문의 구성은 다음과 같다. 2장에서 본 연구의 선행연구에 대해 살펴본 후, 3장에서는 본 연구에서 해결하고자 하는 램프구간의 POMDP 모델을 소개한다. 4장에서는 제안한 모델을 기반으로 학습한 자율 주행 자동차의 정책을 분석하고 평가한 후 5장에서는 결론을 맺는다. 본 논문에서 사용한 모든 기호는 Nomenclature와 Subscripts에서 확인할 수 있다.
2. 선행연구
2.1 심층 강화학습 알고리즘
심층 강화학습은 강화학습에 심층 학습의 장점을 결합한 방법으로 게임20), 로봇 제어21), 자율주행 기술10-14) 등과 같이 다양한 분야에 적용되고 있다. 강화학습은 상태 전이 분포 및 보상 함수와 같은 모델의 사용 유무에 따라 Model-based22) 방식과 Model-free 방식으로 구분할 수 있다. 모델의 정보를 사용하지 않는 경우 Model-free 강화학습이 활용될 수 있으며, 이 방식에서 개체(Agent)는 환경과의 직접적인 상호작용을 통해 정책을 학습한다. Model-free 강화학습 알고리즘에는 Q함수를 근사하는 가치 기반(Value-based) 방법과, 개체의 정책을 근사하는 정책 기반(Policy-based) 방법, 그리고 두 방법을 결합한 액터-크리틱(Actor-critic) 방법이 있다.
가치 기반 알고리즘은 상태-행동(State-action) 쌍에 대한 가치를 평가하는 Q-네트워크의 근사를 통해 암묵적인 정책(Implicit policy)을 학습하는 방법이다. 구체적으로, 개체는 별도의 정책 네트워크 없이 각 상태에서 가장 높은 Q 값을 출력하는 행동을 선택하는 방식을 채택한다. 대표적인 예로 DQN(Deep Q-Network)23)과 DDQN(Double DQN)24) 알고리즘이 존재한다.
정책 기반 알고리즘은 상태 정보에 대한 행동을 직접적으로 출력하는 정책 네트워크를 바로 학습하는 방법이다. 정책의 성능을 판단할 수 있는 목표 함수를 설정하고 신경망의 가중치에 대한 경사 상승법(Gradient ascent)을 통해 정책을 최적화한다. 대표적인 예로 REINFORCE25)와 DPG(Deterministic Policy Gradient)26) 알고리즘이 있다.
가치 기반 방법과 정책 기반 방법을 결합한 액터-크리틱 방법은 개체의 행동을 결정하는 액터 네트워크와 행동에 대한 평가를 내리는 크리틱 네트워크를 통해 정책을 학습하는 방법이다. 대표적으로 본 논문에서 다룰 PPO17), DDPG18), TD319) 알고리즘이 있다.
2.2 심층 강화학습 기반 자율주행 연구
동적인 도로 환경에 성공적인 자율주행 정책의 필요성이 대두됨에 따라 심층 강화학습 기반의 자율주행 정책 연구가 활발히 진행되고 있다.27,28) 이는 1차선 도로와 같이 상대적으로 단순한 도로 주행을 위한 정책을 시작으로, Stop-and-go wave 현상 해결14) 및 차선 변경을 통한 추월 정책 구축29) 같이 특정 주행 특성 학습을 위한 방향으로 발전되어 오고 있다. 이를 위해 많은 연구들은 해당 목적 달성을 위한 MDP 모델의 설계를 고려한다.
최근에는 보다 복잡한 도로 구조 및 교통 정체가 발생하는 환경에서의 성공적인 자율주행 정책 구축 연구가 다방면으로 이뤄지고 있다. 예를 들어, Rodrigo 등11)은 교차로에서 심층 강화학습 방식의 자율 주행 자동차가 성공적으로 주행함을 보였으며, Eom 등12)은 우선적 경험 재생 기반 심층 강화학습 알고리즘으로 학습된 개체가 차량 정체 구간을 성공적으로 주행함을 보였다.
이와 같이 최근 복잡한 도로 환경을 고려하는 자율주행 정책 연구가 활발히 진행되고 있다. 이에 본 연구에서는 차선 감소로 인해 복잡한 도로 환경이 조성되는 램프구간 병합지점에서 성공적인 합류 정책 구축을 목표로 한다.
2.3 램프구간을 고려하는 자율주행 연구
램프구간에서 자율 주행 자동차의 잘못된 의사결정은 충돌 사고 및 교통 정체로 이어질 수 있다.30) 램프구간 병합을 위한 기존 수학적 모델 접근 방식31-33)의 한계를 보안하기 위해 교통 시스템을 활용한 연구나 강화학습 기반의 커넥티드 차량 CAV(Connected Automated Vehicle)에 대한 많은 연구가 이루어졌다. 교통 시스템을 활용한 대표적인 연구로는 램프 차선의 신호 조절(Ramp metering)을 통해 진입하는 차량의 흐름을 조절하는 방법34,35) 및 가변 속도 제한과 본선 신호 조절을 통해 본 차선의 차량 흐름을 조절하는 방법36,37) 등이 고려되고 있다. 해당 연구들은 교통 시스템을 통해 램프구간에서의 교통 정체를 완화할 수 있음을 보였지만, 이는 차량 제어에 직접 관여하지 않기 때문에 수동적인 차량 제어를 필요로 하며, 교통 정보 획득을 위해 광범위한 도로 상태 정보를 파악해야 한다는 어려움이 존재한다.
자율 주행 자동차의 직접적인 의사결정을 고려하는 강화학습 기반의 연구로는 CAV가 활용될 수 있다.38,39) Yang 등38)은 램프구간 CAV의 분포에 따른 교통 흐름을 시뮬레이션 하였고, Cellular automata 모델을 사용하여 CAV의 도입이 교통 효율성과 안전성 증진, 충돌 위험을 줄이는 데 기여함을 확인하였다. 또한 Wang 등39)은 그래프 기반의 차량 간 정보 공유를 하는 CAV가 합류 주행을 성공적으로 수행함을 보였다. 해당 연구들은 자율적 의사결정을 수행하는 자율 주행 자동차의 도입을 통해 효율적인 합류가 가능함을 보였지만, 모든 개체의 상태 정보 획득을 위해 인접 차량 혹은 인프라와의 통신이 가능한 추가적인 모듈을 요구하며, 통신 지연과 같은 추가적인 문제가 발생할 수 있다는 우려가 존재한다.40)
이에 본 연구에서는 모든 개체의 상태 정보를 기반으로 문제를 정의하던 기존 강화학습 연구들9,41-43)과 달리 추가적인 통신 모듈의 고려 없이 자율 주행 자동차의 관측 범위 내 정보(Observation)만을 활용하여 의사결정이 가능한 POMDP 기반의 자율주행 정책을 고려한다.
3. 합류를 위한 심층 강화학습 기반 자율 주행 자동차 학습 전략
강화학습 문제는 MDP를 통해 모델링할 수 있다. MDP에서는 개체가 환경의 모든 상태 정보를 관측 가능(Fully observable)하다는 가정이 존재하지만 실제 대부분의 경우 환경의 상태를 완전히 관찰하는 것은 불가능하다. 특히 자율주행과 같이 현실적인 환경에서는 모든 상태 정보를 완벽하게 관측하는 것이 제한되기 때문에 본 연구에서는 부분적인 상태 정보를 기반으로 의사결정을 수행하는 POMDP를 통해 강화학습 문제를 정의하였다.
POMDP는 튜플 < S, A, T, O, Ω, R, γ>로 정의되며 st∈S는 도로 환경의 상태 정보, at∈A는 자율주행 개체의 주행 행동, T(st+1 ∣ st,at)는 상태 전환 확률(State transition probability), ot∈O는 특정 t시점의 상태 st에서 자율주행 개체가 관측 가능한 정보, Ω(ot ∣ st)는 관측 확률(Observation probability)을 의미한다. 또한 R(st,at,st+1)은 보상 함수이며, γ∈[0,1)는 시간에 따른 감가율(Discount factor)을 의미한다.
3.1 도로 환경
본 연구에서는 합류 정책 학습을 위해 Fig. 1과 같이 도로 내 차선이 증가/감소하는 전환 지점(Transition point)이 포함된 도로 구조를 고려한다. 구체적으로, M개의 전환 지점 이 포함된 도로에 총 N대의 차량 C={c1,c2, … ,cN}이 주행하는 환경을 고려한다. 해당 도로 환경에서는 램프 차선(On-ramp)에서 본 차선(Main lane)으로 합류가 필수적이고, 차선 감소로 인한 교통 용량(Road capacity)의 감소로 불규칙한 도로 환경이 조성된다. 이때, 자율 주행 자동차 AV(Autonomous Vehicle)는 안전하고 효율적인 합류 정책 학습을 목적으로 한다. 이를 위해 자율 주행 자동차는 분기점(Junction)에서 분기하여 램프 차선으로 진입하고, 비자율 주행 자동차 NAV(Non-Autonomous Vehicle)는 분기하지 않고 본 차선 경로로 진입하는 도로 환경을 고려한다.

Road structure with on-ramp merging zone
도로 내 차량 집합 C=CNAV ∪ CAV은 N-1대의 비자율 주행 자동차 CNAV={ci ∣ i≠N}와 1대의 자율 주행 자동차 CAV={ci ∣ i = N}로 구성된다. 이때, 도로 상태 정보 st는 다음과 같이 정의된다.
| (1) |
식 (1)에서 vt = [vt,1, vt,2, … ,vt,N]⊤는 도로 내 모든 차량들의 절대 속도, pt = [pt,1, pt,2, … ,pt,N]⊤는 모든 차량들의 절대 위치를 의미한다. 또한 kt = [kt,1, kt,2, … ,kt,N]⊤는 각 차량이 위치한 도로의 차선 번호, dt = [dt,1, dt,2, … ,dt,N]⊤는 각 차량별 가장 가까운 전방 전환 지점까지의 거리를 의미한다.
3.2 합류 정책 학습을 위한 Partially Observable Markov Decision Process
본 연구에서는 부분적인 관측 정보를 통한 개체의 의사결정을 위해 POMDP 기반의 강화학습 문제를 고려한다. 자율 주행 자동차는 본인이 위치한 차선을 포함하여 총 H개의 차선과 개체가 위치한 절대 위치 기준 전, 후방 각각 V만큼의 거리를 관측할 수 있으며 이를 관측 가능한 영역(Observable area)이라고 정의한다(Fig. 2(a)). 관측 가능한 영역 내 차량은 관측 가능한 차량(Observable vehicle)으로 정의하며, 집합 Ct,obs로 표기한다. 이때, Ct,obs은 도로 내 비자율 주행 자동차 ci∈CNAV와 관측 가능한 영역에 대해 식 (2)와 같은 조건을 만족한다.
| (2) |

Illustrative examples of the observation space when H=3 (a) the observable area of an autonomous vehicle, and (b) traffic density per lane
또한 관측 가능한 차량 집합은 전방 차량 집합 Lt과 후방 차량 집합 Ft으로 나뉠 수 있으며, 다음과 같이 정의한다.
| (3) |
식 (3)에서 Lt,h ⊂ Lt 및 Ft,h ⊂ Ft는 각 차선 h별 관측 가능한 영역 내 전방 및 후방 차량 집합을 의미한다. 이때, 전, 후방 차선별 관측된 차량 집합에서 자율 주행 자동차와 가장 가까운 차량을 Leader lt,h ∈ Lt,h와 Follower ft,h ∈ Ft,h로 정의한다.
Observation: 자율 주행 자동차의 t시점 관측 정보 ot∈O는 다음과 같이 정의한다.
| (4) |
식 (4)에서 vt,N은 자율 주행 자동차의 절대 속도이다. Δvt = [Δvt,l1, Δvt,l2, … ,Δvt,lH, Δvt,f1, Δvt,f2, … ,Δvt,fH]⊤는 자율 주행 자동차와 각 차선 Leader, Follower와의 상대 속도(Δvt,n=vt,n-vt,N), Δpt = [Δpt,l1, Δpt,l2, … ,Δpt,lH, Δpt,f1, Δpt,f2, … ,Δpt,fH]⊤는 각 차선 Leader, Follower와의 상대 거리(Δpt,n=pt,n-pt,N)를 의미한다. ρt = [ρt,1, ρt,2, … ,ρt,H]⊤는 자율 주행 자동차의 전방 관측 범위 내 차선별 차량 밀도를 나타낸다. 특정 차선 h에서 차량 밀도 ρt,h는 전방 관측 범위 V 대비하여 해당 차선에서 차량이 차지한 비율을 의미하며 다음과 같다(Fig. 2(b)).
| (5) |
식 (5)에서 |Lt,h|는 관측된 차량 대수, ei는 해당 차선의 i번째 차량의 길이, δ0는 차량 간 최소 안전 거리를 의미한다.
마지막으로 ζt = [ζt,1, ζt,2, … ,ζt,H]⊤는 자율 주행 자동차의 전방 관측 가능 영역 내 차선의 존재성 여부를 나타낸다. 이는 관측 가능 범위인 V와 전방 전환 지점까지의 남은 거리 dt에 의해 정의되며, Fig. 3을 통해 확인할 수 있다. 자율 주행 자동차의 전방 관측 범위 내 차선이 존재하다가 끊어지는 경우라면 dt-V로 정의되며, 확장되는 경우 -(dt-V)로 정의된다. 또한 차선이 자율 주행 자동차를 기준으로 이미 연결되어 있는 경우엔 V로 정의되며, 차선이 존재하지 않는 경우 -V로 정의된다. 이때, 각 요소들은 [-V, +V]의 범위에서 정의된다.

An illustrative example of observing lane existence
Action: 자율 주행 자동차의 t시점 행동 at∈A은 다음과 같다.
| (6) |
식 (6)에서 at,acc는 가속도 조절 행동을 의미하고, at,lc는 차선 변경(Lane change) 행동을 의미한다. 가속도 조절 행동 at,acc∈[amin,amax]은 최소 가속도 amin과 최대 가속도 amax의 연속적인 범위 내 값을 가진다. 차선 변경 행동 at,lc ∈ Alc={-1,0,1}는 이산적인 값을 가지며 각각의 값은 자율 주행 자동차의 차선 변경 방향을 의미한다. 구체적으로, at,lc = -1인 경우 오른쪽으로 차선 변경, at,lc = 1인 경우 왼쪽으로 차선 변경, at,lc = 0인 경우 차선 유지 행동을 수행한다. 행동 결정에 대한 알고리즘은 Appendix A1에서 구체적으로 확인할 수 있다.
Reward: 자율 주행 자동차의 t시점 보상 rt은 현재 상태 st, 현재 행동 at, 다음 상태 st+1에 대한 함수의 형태 rt = R(st,at,st+1)로 정의되며 각 보상항과 처벌항의 선형 조합으로 이루어진다.
| (7) |
식 (7)에서 Rt,i∈{1,…,6}는 보상항 또는 처벌항을 의미하며 ηi∈{1,…,6}는 각 항에 대한 계수를 의미한다.
첫 번째 항인 Rt,1은 자율 주행 자동차의 t시점 가속 행동 at,acc로 인한 t+1시점의 자율 주행 자동차의 속도 vt+1,N에 관한 항으로, 목표 속도 v*에 가깝게 주행하면서 제한 속도 vlimit은 초과하지 않는 주행 행동을 학습하도록 한다.
| (8) |
식 (8)에서 자율 주행 자동차는 목표 속도 v*에 가깝게 주행할 경우 최대의 양의 보상을 획득하며, 목표 속도를 초과할 경우 양의 보상은 선형적으로 감소하게 된다. 또한, 제한 속도 vlimit를 초과하여 주행하게 될 경우 페널티를 받게 된다.
무의미한 차선 변경에 관한 처벌항 Rt,2는 자율 주행 자동차가 차선 변경 행동(|at,lc|=1)을 하는 경우에만 활성화되며 아래와 같이 정의한다.
| (9) |
식 (9)에서 은 자율 주행 자동차와 동일 차선(Same lane)의 Leader를 의미한다. 는 t시점 자율 주행 자동차와 동일 차선 Leader와의 상대 거리를 의미하고, 는 다음 시점(t+1)에서 자율 주행 자동차와 동일 차선 Leader와의 상대 거리를 의미한다. 이때, 차선 변경 행동 전, 후 상대 거리 차이가 음수인 경우() 무의미한 차선 변경으로 간주하여 페널티를 부여한다(Fig. 4).

An illustrative example of a penalty resulting from the meaningless lane change of an autonomous vehicle
자율 주행 자동차는 Rt,3와 Rt,4를 통해 차량 간 안전 거리를 유지하며 안전한 주행 행동을 학습한다. 구체적으로, Rt,3는 자율 주행 자동차가 동일 차선 Leader와의 안전 거리 를 침범하지 않는 주행을 하도록 유도하며, Rt,4는 자율 주행 자동차의 차선 변경이 동일 차선 Follower와의 안전 거리 를 침범하지 않도록 유도한다(Fig. 5). Rt,3와 Rt,4는 다음과 같이 정의된다.
| (10) |
| (11) |

Leader/Follower safety distance for an autonomous vehicle
자율 주행 자동차는 식 (10)을 통해 주행 시 Leader와의 안전 거리를 침범하는 경우 페널티를 받으며, 식 (11)을 통해 차선 변경 행동이 Follower와의 안전 거리를침범하는 경우 페널티를 받게 된다. 이때, 안전 거리 와 는 다음과 같이 정의된다.
| (12) |
| (13) |
식 (12)와 (13)에서 δ0는 최소 안전 거리를 나타내며, t*는 사고 방지를 위한 최소 시간이다. 또한 와 는 각각 t+1시점에서 동일 차선 Leader와 Follower의 절대 속도를 의미한다.
자율 주행 자동차는 Rt,5를 통해 지연된 합류 행동을 약화하며, Rt,5는 다음과 같이 정의된다.
| (14) |
식 (14)에서 은 자율 주행 자동차가 위치한 차선의 번호이며, 는 자율 주행 자동차가 위치한 차선에서 전방 램프구간 전환지점까지 주행 가능 거리로 계산되는 차선의 존재성에 대한 값을 의미한다. 즉, 자율주행 자동차가 전환지점과 가까운 지점에서 합류를 수행할수록 지연된 합류로 간주하여 높은 페널티를 부여한다. 교통 밀도 가중치 μt+1는 본 차선의 교통 밀도가 높아 차선 변경이 불가할 때 Rt,5로 인한 페널티를 완화하며, 다음과 같이 정의된다.
| (15) |
식 (15)에서 Y은 램프구간의 길이이고, |Ct+1,Y|은 램프구간 본 차선의 차량 대수, ei는 램프구간 본 차선의 차량 집합 Ct+1,Y내 i번째 차량의 길이를 의미한다. 해당 가중치는 램프구간 본 차선에 차량 대수에 반비례하는 값을 가진다. 즉, 본 차선에 교통 정체가 존재하여 차선 변경이 어려운 경우 페널티의 정도를 완화한다. 교통 밀도 가중치 μt+1에 대한 구체적인 그림은 Fig. 6을 통해 확인할 수 있다.

Illustrative examples of the weighting factor μt+1. (a) High weighted case, and (b) low weighted case
마지막 항인 Rt,6은 사고 발생 관련 처벌항으로 차량 사고가 발생하는 경우 페널티를 부여하며 식 (16)과 같이 정의된다.
| (16) |
본 연구에서, 사고 발생은 최악의 주행 행동으로 고려한다. 이에 해당항의 가중치인 η6를 가장 높은 값으로 설정함으로써, 사고 발생 행동 수행 시 개체에게 가장 큰 페널티를 부여한다.
4. 성능 측정 및 분석
본 절에서는 심층 강화학습 기반으로 학습한 자율 주행 자동차의 정책을 분석하고 평가한다. 먼저, 학습을 진행한 시뮬레이션 환경과 학습 알고리즘 설정에 대해 살펴본다. 이후 심층 강화학습 기반(RL-based) 환경과 제어이론 기반 환경에서의 램프구간 자율주행 정책 성능을 평가하고 주행 경향성에 대해 분석한다.
4.1 시뮬레이터 및 학습 환경 설정
본 연구에서는 자율 주행 자동차의 학습 환경 구성과 실험을 위해 교통 시뮬레이터 SUMO45) 기반의 FLOW46) 프레임워크를 사용한다. 주행 환경 설정은 도로 내 전환 지점 M=2, 램프구간의 길이 Y=35m로 설정하며, 도로 내 차량 대수 N=16으로, 1대의 자율 주행 자동차와 15대의 비자율 주행 자동차가 공존하는 환경을 고려한다. 또한, 자율 주행 자동차의 관측 범위 V=30m, 관측 가능한 차선 H=3으로 설정하였으며, 도로 내 모든 차량들의 목표 속도 v*는 49.27km/h이고, 제한 속도 vlimit은 116km/h이다. 이때, 자율 주행 자동차의 최대 및 최소 가속도는 각각 amax=5.4m/s2, amin=-5.4m/s2와 같이 설정하였다. 주행 정책의 학습은 총 3000번의 에피소드 동안 진행하며, 에피소드의 길이 E는 학습 안정화를 위한 Warm-up 시간 EW=125ts과 정책을 학습하는 시간 Eeps=3000ts의 합(E=EW+Eeps)으로 구성된다. 1ts=0.1s이다. 실험을 진행한 환경과 구체적인 시뮬레이터 Hyperparameter 설정은 Appendix A2와 A3에서 확인할 수 있다.
시뮬레이션 중 비자율 주행 자동차는 Intelligent Driver Model(IDM)44) 제어기에 의해 가속도 조절 의사결정을 수행하면서 본 차선으로 주행한다.
4.2 자율 주행 자동차의 주행 정책 설정
본 연구에서는 제안한 POMDP 기반의 자율주행 정책의 주행 성능 비교를 위해 전통적인 자율주행 정책 방법 중 하나인 제어이론 기반 정책과의 비교를 수행한다. 또한, 심층 강화학습 기반의 포괄적인 주행 특성 분석을 위해 액터-크리틱 알고리즘인 PPO, DDPG, TD3로 학습된 주행 정책을 고려한다.
Control-theoretic: 전통적인 제어이론 방식의 주행을 수행하는 자율주행 정책으로, 본 연구에서 고려하는 제어이론 기반 차량은 IDM44)과 Gipps47)를 통한 가속도 조절을 수행하며, LC201348) 모델에 기반한 차선 변경 행동을 고려한다. 해당 자율주행 정책은 기존 자율주행 정책에 대한 Baseline 성능을 제공한다.
RL-based: 본 연구에서는 심층 강화학습 기반 자율 주행 자동차의 주행 특성 분석을 위해 아래와 같은 다양한 학습 알고리즘을 고려한다.
- ⦁ PPO17): 확률적 정책(Stochastic policy)을 고려하는 알고리즘으로 Surrogate target에 기반한 정책 학습을 수행하며 이때, 액터 네트워크가 큰 폭으로 변하지 않게 하기 위해 클리핑된 Surrogate target을 적용한다. 본 알고리즘은 자율 주행 자동차가 확률적인 정책을 고려할 때의 주행 정책을 제공한다.
- ⦁ DDPG18): 결정론적인 정책(Deterministic policy)을 고려하는 알고리즘으로, 기존의 정책 기반 알고리즘인 DPG에 DQN기반의 크리틱 네트워크를 적용함으로써, 연속적인 행동 공간(Continuous action space)에서의 의사결정 모델을 학습한다. 해당 방법은 결정론적인 자율주행 정책을 제공한다.
- ⦁ TD319): DDPG의 개선된 알고리즘으로 두 개의 크리틱 네트워크 중 작은 Q값으로 액터 네트워크를 업데이트함으로써, 과대 추정(Overestimation) 문제를 완화한다. 또한 액터 네트워크를 크리틱 네트워크보다 지연하여 업데이트 함으로써 높은 학습 안정성을 제공한다. 해당 알고리즘은 과대 추정 문제가 완화된 결정론적 자율주행 정책을 제공한다.
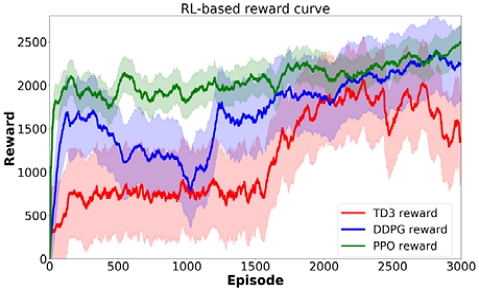
각 알고리즘별 구체적인 Hyperparameter 설정은 Appendix A4에서 확인할 수 있으며, RL-based의 누적 보상 그래프는 Appendix A5에서 확인할 수 있다.
4.3 자율 주행 자동차의 학습 성능 평가
본 절에서는 램프구간에서 자율 주행 자동차가 제어이론 기반으로 주행하는 Control-theoretic 환경과 각 심층 강화학습 알고리즘으로 학습된 정책을 기반으로 주행하는 RL-based 환경을 비교한다. 우선적으로, Control-theoretic 및 RL-based의 자율 주행 자동차 도입 시 램프 차선과 본 차선의 교통 흐름에 미치는 영향을 분석하며, 각 주행 정책별 충돌률을 비교한다. 이후, Control-theoretic 및 RL-based 자율주행 정책의 대표적인 합류 경향성을 분석한다.
램프구간에서의 교통 흐름은 합류를 시도하는 차량의 주행 특성에 따라 다르게 나타날 수 있다. 본 절에서는 서로 다른 자율 주행 자동차의 합류 정책에 따른 본 차선 차량 및 램프 차선 차량의 교통 흐름을 Fig. 7을 통해 분석한다. 해당 그래프는 환경별 5개의 학습 시드에서 모든 차량의 시작 위치가 매번 랜덤하게 결정되는 에피소드를 독립적으로 각 10번씩 시행한 실험의 결과이다. 그래프에서 실선은 RL-based 환경, 점선은 Control-theoretic 환경의 도로 구간별 평균 속도를 의미하며, 음영은 각 환경의 학습 시드별 1차 표준 편차를 의미한다. 또한, 검정색 가로 점선은 목표 속도이며, 회색 세로 점선은 도로가 병합되기 시작하는 지점을 의미한다.

Comparison of traffic flow across the learning environments: (a) average speed of an autonomous vehicle in the on-ramp lane, (b) average speed of non-autonomous vehicles in the main lane
학습 환경에 따른 램프 차선의 차량 즉, 자율 주행 자동차의 도로 구간별 평균 속도는 Fig. 7(a)을 통해 확인할 수 있다. 해당 그래프를 통해 Control-theoretic 환경에서 IDM 제어기반의 자율 주행 자동차는 162m 구간에서 큰 폭으로 감속하는 반면, RL-based 환경의 자율 주행 자동차는 램프구간을 통과하는 동안 비교적 작은 폭의 속도 변화를 보이는 것을 확인할 수 있다. 이러한 자율 주행 자동차의 합류 특성 차이는 본 차선 교통 흐름에 영향을 미치며, 본 차선 비자율 주행 자동차에 대한 위치별 평균 속도 그래프인 Fig. 7(b)을 통해 확인할 수 있다. 해당 그래프에서 RL-based 환경의 비자율 주행 자동차 평균 속도가 Control-theoretic 환경의 비자율 주행 자동차 평균 속도에 비해 모든 구간에서 높은 것을 확인할 수 있다. 이는 심층 강화학습 알고리즘으로 학습된 자율 주행 자동차의 합류 주행이 본 차선 교통 흐름 악화에 미치는 영향이 적은 것을 의미한다. Table 1은 Fig. 7 그래프에 대해 평균 속도와 1차 표준 편차, 충돌률을 정량적으로 수치화한 표이다.

Average speed and collision rate of an autonomous vehicle in the on-ramp lane and non-autonomous vehicles in the main lane by learning environment
해당 표를 통해 Control-theoretic 환경에 비해 RL-based의 모든 환경에서 램프 차선 및 본 차선의 교통 흐름이 빠르게 조성되는 것을 확인할 수 있다. 구체적으로 RL-based의 램프 차선 자율 주행 자동차 속도는 Control-theoretic에 비해 평균 4.52% 높았고, 본 차선 비자율 주행 자동차의 속도는 평균 2.13% 높은 것을 확인하였다. 충돌률 또한 Control-theoretic 환경은 평균 45%로 빈번한 충돌을 일으켰지만 RL-based 환경에선 평균 4.6%의 낮은 충돌률로 Control-theoretic에 비해 안전함을 확인할 수 있다. 이때, RL-based의 환경에서의 교통 흐름이 학습 알고리즘에 작은 변동성을 보이는 것을 확인할 수 있는데, 이는 제안한 POMDP가 적용 알고리즘에 관계없이 강건한 주행 정책을 구축할 수 있다는 것을 의미한다. 결과적으로 제안된 POMDP를 통한 RL-based 자율 주행 자동차의 도입이 램프구간에서 속도 조절 측면으로 효율적임과 동시에 안전한 도로 환경을 조성할 수 있음을 확인할 수 있다.
본 절에서는 RL-based 및 Control-theoretic 환경에서 대표적인 합류 상황에 대한 정성적 분석을 수행한다. Fig. 8(a)은 RL-based 환경에서 DDPG 알고리즘의 자율주행 정책과 Control-theoretic 환경에서 IDM 제어기의 대표적인 합류 상황에 대해 Time steps 별로 기록한 스냅샷 결과이며, Fig. 8(b)은 각 환경에서 특정 에피소드의 램프구간 위치별 평균 속도 그래프이다. 그래프의 회색 점선은 각각의 Time steps을 의미한다. Control-theoretic 정책의 경우 속도 조절 없이 이전 속도를 유지한 채 주행하다가 ④ ts=45에서 전환 지점인 162m 부근에 도달하여 감속하기 시작하는 것을 확인할 수 있다. 반면 RL-based의 경우 ② ts=20 부터 서서히 감속을 시작하여 본 차선으로 차선 변경할 공간을 기다리고, ③ ts=30에서 차선 변경을 통해 합류를 수행한 후 전방 차량과의 간격을 유지한 채 주행한다. 이러한 주행의 결과로 합류를 완료한 ⑤ ts=60에서 두 환경 간 속도 차이는 크게 발생하는 것을 그래프를 통해 확인할 수 있다. 결과적으로 RL-based 환경이 Control-theoretic 환경에 비해 속도 조절을 잘 수행하여 안정적인 합류를 한다는 것을 의미한다.

Comparative analysis of merge tendency in autonomous driving strategy: (a) driving snapshots by time steps and (b) average speed by position
5. 결 론
본 연구에서는 심층 강화학습을 통해 램프구간을 안전하고 효율적으로 주행할 수 있는 자율주행 합류 정책을 위한 POMDP를 제안하였다. PPO, DDPG, TD3 심층 강화학습 알고리즘으로 자율 주행 자동차를 학습하여 제어이론 기반의 자율 주행 자동차와 램프구간 주행 성능을 비교, 분석하였다. 제안한 POMDP를 통해 학습된 자율 주행 자동차가 존재하는 RL-based 환경에서는 Control-theoretic 환경 대비 램프 차선에서 자율 주행 자동차의 속도를 4.52% 향상시켰으며, 본 차선의 비자율 주행 자동차의 교통 흐름은 2.13% 향상시켰다. 충돌률도 RL-based 환경이 Control-theoretic 환경에 비해 평균 41.4% 낮은 수치를 달성하는 것을 확인하였다. 이때, RL-based의 자율주행 정책이 학습 알고리즘에 큰 변동 없이 Control-theoretic 주행 정책보다 우수한 주행 성능을 보이는 것을 확인함으로써, 제안한 POMDP를 통한 심층 강화학습 기반의 자율주행 정책이 기존의 제어이론 기반의 방식보다 변동성 없이 효율적이면서 안전한 합류가 가능하다는 것을 보였다.
Nomenclature
| S : | state space |
| A : | action space |
| T : | state transition probability |
| O : | observation space |
| R(st,at,st+1) : | reward function |
| ρt,h : | vehicle density on ahead lane h |
| at,acc : | acceleration action, m/s2 |
| amin : | minimum acceleration, m/s2 |
| Y : | length of on-ramp merging zone |
| : | a set of transition points |
| C : | a set of vehicles |
| cN : | an autonomous vehicle |
| V : | observable distance, m |
| Lt : | a set of vehicles in the ahead |
| Ft : | a set of vehicles in the rear |
| st : | state |
| at : | action |
| ot : | observation |
| Ω : | observation probability |
| γ : | discount factor |
| ζt,h : | lane existence on ahead lane, h |
| at,lc : | lane change action |
| amax : | maximum acceleration, m/s2 |
| dt : | distance to transition point, m |
| M : | the number of transition points |
| N : | the number of vehicles |
| ci (i≠N) : | non autonomous vehicles |
| H : | the number of observable lanes |
| Ct,obs : | a set of observable vehicles |
| lt,h : | leader in lane h |
| ft,h : | follower in lane h |
| ei : | length of i–th car, m |
| δ0 : | min gap between vehicles, m |
| v* : | desired speed, km/h |
| vlimit : | limited speed, km/h |
| : | safe distance from same lane leader, m |
| : | safe distance from same lane follower, m |
| |Ct,Y| : | number of vehicles in the main lane |
| |Lt,h| : | the number of vehicles in the lane h |
| μt : | weight for main lane vehicle density |
| E : | time steps of episode |
| EW : | time steps for the warm-up stage |
| Eeps : | time steps for the training stage |
Subscripts
| t : | time steps |
| h : | h-th lane |
| : | same lane number |
| i : | number assigned to each lane’s vehicles |
| : | leader in the same lane |
| : | follower in the same lane |
Acknowledgments
이 성과는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구임(RS-2023-00278812).
References
- Ministry of Land, Infrastructure and Transport, Mobility Transformation Road Map(2022), http://www.molit.go.kr/USR/NEWS/m_71/dtl.jsp?lcmspage=1&id=95087208, , 2023.
-
C. Zhan, J. Qi, Y. He, M. Shafique and J. Zhao, “Collision-Free Merging Control via Trajectory Optimization for Connected and Autonomous Vehicles,” Transportation Research Record, 2024.
[https://doi.org/10.1177/03611981231224739]

-
J. Zhu and I. Tasic, “Safety Analysis of Freeway On-Ramp Merging with the Presence of Autonomous Vehicles,” Accident Analysis & Prevention, Vol.152, Paper No.105966, 2021.
[https://doi.org/10.1016/j.aap.2020.105966]
-
X. Nie, Y. Liang and K. Ohkura, “Autonomous Highway Driving Using Reinforcement Learning with Safety Check System Based on Time-to-Collision,” Artificial Life and Robotics, Vol.28, pp.158-165, 2023.
[https://doi.org/10.1007/s10015-022-00846-8]
-
D. Chen, M. Hajidavalloo, Z. Li, K. Chen, Y. Wang, L. Jiang and Y. Wang, “Deep Multi-Agent Reinforcement Learning for Highway On-Ramp Merging in Mixed Traffic,” IEEE Transactions on Intelligent Transportation Systems, Vol.24, No.11, pp.11623-11638, 2023.
[https://doi.org/10.1109/TITS.2023.3285442]
-
F. Ahmad, “Deep Image Retrieval Using Artificial Neural Network Interpolation and Indexing Based on Similarity Measurement,” CAAI Transactions on Intelligence Technology, Vol.7, No.2, pp.200-218, 2022.
[https://doi.org/10.1049/cit2.12083]
-
C. Humer, S. Höll, C. Kralovec and M. Schagerl, “Damage Identification Using Wave Damage Interaction Coefficients Predicted by Deep Neural Networks,” Ultrasonics, Vol.124, Paper No.106743, 2022.
[https://doi.org/10.1016/j.ultras.2022.106743]
-
F. Feit, A. Metzger and K. Pohl, “Explaining Online Reinforcement Learning Decisions of Self-Adaptive Systems,” IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS), 2022.
[https://doi.org/10.1109/ACSOS55765.2022.00023]
-
X. Zhang, L. Wu, H. Liu, Y. Wang, H. Li and B. Xu, “High-Speed Ramp Merging Behavior Decision for Autonomous Vehicles Based on Multiagent Reinforcement Learning,” IEEE Internet of Things Journal, Vol.10, No.24, pp.22664-22672, 2023.
[https://doi.org/10.1109/JIOT.2023.3304890]
-
D. Lee and M. Kwon, “Stability Analysis in Mixed-Autonomous Traffic with Deep Reinforcement Learning,” IEEE Transactions on Vehicular Technology, Vol.72, No.3, pp.2848-2862, 2023.
[https://doi.org/10.1109/TVT.2022.3215505]
-
R. Gutiérrez-Moreno, R. Barea, E. López-Guillén, J. Araluce and L. Bergasa, “Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator,” Sensors, Vol.22, No.21, Paper No.8373, 2022.
[https://doi.org/10.3390/s22218373]
-
C. Eom, D. Lee and M. Kwon, “Autonomous Driving Strategy for Bottleneck Traffic with Prioritized Experience Replay,” The Journal of Korean Institute of Communications and Information Sciences, Vol.48, No.6, pp.690-703, 2023.
[https://doi.org/10.7840/kics.2023.48.6.690]
-
T. Kim, H. Lee, K. Kim and S. Hwang, “Path-Following Strategies for 4-Wheel Independent Steering EVs Using PPO Reinforcement Learning and Turning Radius Gain,” Transactions of KSAE, Vol.31, No.8, pp.575-584, 2023.
[https://doi.org/10.7467/KSAE.2023.31.8.575]
-
D. Lee and M. Kwon, “Combating Stop-and-Go Wave Problem at a Ring Road Using Deep Reinforcement Learning,” The Journal of Korean Institute of Communications and Information Sciences, Vol.46, No.10, pp.1667-1682, 2021.
[https://doi.org/10.7840/kics.2021.46.10.1667]
-
A. Folkers, M. Rick and C. Büskens, “Controlling an Autonomous Vehicle with Deep Reinforcement Learning,” IEEE Intelligent Vehicles Symposium (IVS), 2019.
[https://doi.org/10.1109/IVS.2019.8814124]
-
D. Isele, A. Nakhaei and K. Fujimura, “Safe Reinforcement Learning on Autonomous Vehicles,” IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018.
[https://doi.org/10.1109/IROS.2018.8593420]
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford and O. Klimov, “Proximal Policy Optimization Algorithms,” arXiv preprint, arXiv:1707.06347, , 2017.
- T. Lillicrap, J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver and D. Wierstra, “Continuous Control with Deep Reinforcement Learning,” International Conference on Learning Representations (ICLR), 2016.
- S. Fujimoto, H. Hoof and D. Meger, “Addressing Function Approximation Error in Actor-Critic Methods,” International Conference on Machine Learning (ICML), 2018.
-
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. Van Den Driessche, T. Graepel and D. Hassabis, “Mastering the Game of Go without Human Knowledge,” Nature, Vol.550, pp.354-359, 2017.
[https://doi.org/10.1038/nature24270]
-
J. Kover, J. Bagnell and J. Peters, “Reinforcement Learning in Robotics: A Survey,” The International Journal of Robotics Research, Vol.32, No.11, pp.1238-1274, 2013.
[https://doi.org/10.1177/0278364913495721]
-
A. Nagabandi, G. Kahn, R. Fearing and S. Levine, “Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning,” IEEE International Conference on Robotics and Automation (ICRA), 2018.
[https://doi.org/10.1109/ICRA.2018.8463189]
-
V. Mnih, K. Kavukcuoglu, D. Silver, A. Rusu, J. Veness, M. Bellemare, A. Graves, M. Riedmiller, A. Fjdjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg and D. Hassabis, “Human-Level Control through Deep Reinforcement Learning,” Nature, Vol.518, pp.529-533, 2015.
[https://doi.org/10.1038/nature14236]
-
H. Hasselt, A. Guez and D. Silver, “Deep Reinforcement Learning with Double Q-Learning,” AAAI Conference on Artificial Intelligence, 2016.
[https://doi.org/10.1609/aaai.v30i1.10295]
-
R. Williams, “Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning,” Machine Learning, Vol.8, No.3-4, pp.229-256, 1992.
[https://doi.org/10.1007/BF00992696]
- D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra and M. Riedmiller, “Deterministic Policy Gradient Algorithms,” International Conference on Machine Learning (ICML), 2014.
-
B. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. Sallab, S. Yogamani and P. Pérez, “Deep Reinforcement Learning for Autonomous Driving: A Survey,” IEEE Transactions on Intelligent Transportation Systems, Vol.23, No.6, pp.4909-4926, 2022.
[https://doi.org/10.1109/TITS.2021.3054625]
- J. Lee and J. Choi, “Deep Reinforcement Learning Based Lane Changing System,” KSAE Spring Conference Proceedings, 2019.
-
Y. Song, H. Lin, E. Kaufmann, P. Dürr and D. Scaramuzza, “Autonomous Overtaking in Gran Turismo Sport Using Curriculum Reinforcement Learning,” IEEE International Conference on Robotics and Automation (ICRA), 2021.
[https://doi.org/10.1109/ICRA48506.2021.9561049]
-
Y. Fang, H. Min, X. Wu, W. Wang, X. Zhao and G. Mao, “On-Ramp Merging Strategies of Connected and Automated Vehicles Considering Communication Delay,” IEEE Transactions on Intelligent Transportation Systems, Vol.23, No.9, pp.15298-15312, 2022.
[https://doi.org/10.1109/TITS.2022.3140219]
-
J. Liang, T. Guan, D. Liu, X. Liu, Z. Luan, H. Liu and X. Yuan, “An Optimal Trajectory Planning for Automated On-Ramp Merging,” IET Intelligent Transport Systems, Vol.17, No.5, pp.835-847, 2023.
[https://doi.org/10.1049/itr2.12308]
-
L. Zhang, J. Sun, J. Ma, S. Xu, X. Hu, Z. Li, J. Tang and Y. Wen, “Simulation Study On Ramp Inflow for Hybrid Autonomous Driving,” Physical Communication, Vol.55, Paper No.101932, 2022.
[https://doi.org/10.1016/j.phycom.2022.101932]
-
X. Chen, T. Li, Z. Ma and J. Sun, “Integrated Mainline and Ramp Signal Control for Expressway On-Ramp Bottleneck with Unequal Lane-Setting,” Journal of Intelligent Transportation Systems, Vol.26, No.1, pp.100-115, 2022.
[https://doi.org/10.1080/15472450.2020.1797502]
-
S. Ahn, R. Bertini, B. Auffray, J. Ross and O. Eshel, “Evaluating Benefits of Systemwide Adaptive Ramp-Metering Strategy in Portland, Oregon,” Transportation Research Record, Vol.2021, No.1, pp.47-56, 2007.
[https://doi.org/10.3141/2012-06]
-
I. Papamichail, M. Papageorgiou, V. Vong and J. Gaffney, “Heuristic Ramp-Metering Coordination Strategy Implemented at Monash Freeway, Australia,” Transportation Research Record, Vol.2178, No.1, pp.10-20, 2010.
[https://doi.org/10.3141/2178-02]
-
B. Peng, M. Keskin, B. Kulcsár and H. Wymeersch, “Connected Autonomous Vehicles for Improving Mixed Traffic Efficiency in Unsignalized Intersections with Deep Reinforcement Learning,” Communications in Transportation Research, Vol.1, Paper No.100017, 2021.
[https://doi.org/10.1016/j.commtr.2021.100017]
-
P. Jin, J. Fang, X. Jiang, M. DeGaspari and C. Walton, “Gap Metering for Active Traffic Control at Freeway Merging Sections,” Journal of Intelligent Transportation Systems, Vol.21, No.1, pp.1-11, 2017.
[https://doi.org/10.1080/15472450.2016.1157021]
-
S. Yang, M. Du and Q. Chen, “Impact of Connected and Autonomous Vehicles on Traffic Efficiency and Safety of an On-Ramp,” Simulation Modelling Practice and Theory, Vol.113, Paper No.102374, 2021.
[https://doi.org/10.1016/j.simpat.2021.102374]
- J. Wang, T. Shi, Y. Wu, L. Moreno and L. Sun, “Multi-Agent Graph Reinforcement Learning for Connected Automated Driving,” International Conference on Machine Learning (ICML), 2020.
-
I. Budhiraja, N. Kumar, H. Sharma, M. Elhoseny, Y. Lakys and J. Rodrigues, “Latency-Energy Tradeoff in Connected Autonomous Vehicles: A Deep Reinforcement Learning Scheme,” IEEE Transactions on Intelligent Transportation Systems, Vol.24, No.11, pp.13296-13308, 2023.
[https://doi.org/10.1109/TITS.2022.3215523]
-
G. Li, W. Zhou, S. Lin, S. Li and X. Qu, “On-Ramp Merging for Highway Autonomous Driving: An Application of a New Safety Indicator in Deep Reinforcement Learning,” Automotive Innovation, Vol.6, No.3, pp.453-465, 2023.
[https://doi.org/10.1007/s42154-023-00235-2]
-
S. Zhou, W. Zhuang, G. Yin, H. Liu and C. Qiu, “Cooperative On-Ramp Merging Control of Connected and Automated Vehicles: Distributed Multi-Agent Deep Reinforcement Learning Approach,” IEEE International Conference on Intelligent Transportation Systems (ITSC), 2022.
[https://doi.org/10.1109/ITSC55140.2022.9922173]
-
J. Nan, W. Deng, R. Zhang, Y. Wang, R. Zhao and J. Ding, “Interaction-Aware Planning with Deep Inverse Reinforcement Learning for Human-Like Autonomous Driving in Merge Scenarios,” IEEE Transactions on Intelligent Vehicles, Vol.9, No.1, pp.2714-2726, 2024.
[https://doi.org/10.1109/TIV.2023.3298912]
-
M. Treiber, A. Hennecke and D. Helbing, “Congested Traffic States in Empirical Observations and Microscopic Simulations,” Physical Review E, Vol.62, No.2, pp.1805-1824, 2000.
[https://doi.org/10.1103/PhysRevE.62.1805]
-
P. Lopez, M. Behrisch, L. Walz, J. Erdmann, Y. Flötteröd, R. Hilbrich, L. Lücken, J. Rummel, P. Wagner and E. Wießner, “Microscopic Traffic Simulation Using SUMO,” IEEE International Conference on Intelligent Transportation Systems (ITSC), 2018.
[https://doi.org/10.1109/ITSC.2018.8569938]
-
C. Wu, A. Kreidieh, K. Parvate, E. Vinitsky and A. Bayen, “FLOW: A Modular Learning Framework for Mixed Autonomy Traffic,” IEEE Transactions on Robotics, Vol.38, No.2, pp.1270-1286, 2022.
[https://doi.org/10.1109/TRO.2021.3087314]
-
P. Gipps, “A Behavioral Car-Following Model for Computer Simulation,” Transportation Research Part B: Methodological, Vol.15, No.2, pp.105-111, 1981.
[https://doi.org/10.1016/0191-2615(81)90037-0]
-
J. Erdmann, “SUMO’s Lane-Changing Model,” Modeling Mobility with Open Data, pp.105-123, 2014.
[https://doi.org/10.1007/978-3-319-15024-6_7]
Appendix
Appendix
Algorithm for action selection
System specification
Simulation settings
Hyperparameters
Reward curves for RL-based algorithms