경진 대회를 통한 자율주행 인식 기술 데이터세트 활용성 평가

Copyright Ⓒ 2021 KSAE / 184-04
This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License(http://creativecommons.org/licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium provided the original work is properly cited.
Abstract
In this paper, a well-synchronized dataset with multiple sensor data and reference data is essential in developing AI(Artificial Intelligence) recognition technology. However, it is very expensive to build an autonomous driving recognition dataset. Also, there are technical problems, such as synchronization. Therefore, to provide a better research environment, we constructed a dataset called KODAS(Korea Dataset for Autonomous Solutions) that can contribute to the development of autonomous driving recognition technology. The logging system for the KODAS dataset was developed in-house, and consists of key sensors, such as lidar/camera/RADAR/GPS/INS/odometer. Furthermore, we validated the feasibility of the KODAS dataset by testing the capacity of autonomous driving recognition. It was conducted in three fields: camera-based forward recognition, ranging sensor-based, omnidirectional three-dimensional recognition, and map matching-based localization. Based on the fusion of multiple sensors, this is the first challenge for recognition technology in Korea. We expect that the KODAS dataset will be an objective standard in evaluating the performance of autonomous driving recognition technology.
Keywords:
Automated vehicle, Dataset, Recognition, Challenge, Benchmark, Multi-sensor system키워드:
자율주행차, 데이터세트, 인식, 경진 대회, 벤치마크, 다중센서 시스템1. 서 론
자율주행 안전성을 확보하기 위해 장애물이나 위치인식을 위하여 주변 환경을 판별하는 자율주행 인식에 대한 연구가 활발하게 진행되고 있다. 이러한 인식 기술 개발을 위해서 실제 도로에서 수집한 다양한 센서 데이터와 기준 정보를 포함하고 있는 방대한 데이터세트(Dataset)가 필요하다. 하지만 실제 도로의 데이터를 수집하고 기준 정보를 가공하는 데이터세트를 구축하는 데에는 많은 시간과 인력이 소요된다. 특히 자율주행 인식 기술 데이터세트의 경우는 다양한 센서들을 장착하여야 하고, 다중센서에 대한 보정 값 추출 및 동기화에 대한 기술적인 문제들을 해결하여야 한다. 따라서 다양한 도로 환경, 날씨, 계절, 일광 등을 포함한 방대한 데이터세트의 구축 및 공개는 인식 기술 연구개발을 위한 기초데이터 활용으로 이어질 것이다.
인식 기술을 위한 데이터세트는 관련 연구에 많은 기여가 된다.1) 데이터세트를 활용한 딥러닝 기반 인식 기술은 사람이 판단하는 수준까지 되어 다양한 물체를 인식하고 분류할 수 있게 되었다.2) 하지만 영상 데이터만 가지고는 주변 환경을 완벽하게 인식하지 못하기 때문에 자율주행 인식 기술 데이터세트는 기본적으로 영상 데이터뿐만 아니라 거리 데이터와 위치 데이터를 포함한다. 최근 자율주행 인식 기술은 센서 데이터의 융합을 통해 각 센서의 장단점을 보완함으로써 인식 결과의 성능 향상을 도모하는 방향에서 연구된다. 데이터세트 분야에서도 기존의 데이터세트가 가지고 있는 한계를 극복하고자 여러 데이터세트를 융합하여 다양한 환경을 구축하고 있다. 일례로 Robust Challenge 2018의 개최 목적은 Middlebury, KITTI, MPI Sintel, ETH3D, HD1K, ScanNet, Cityscape, WildDash 데이터세트들을 융합하여 강인한 알고리즘을 개발하는 것이었다. 이 외에도 국외에서는 인식 기술 개발을 장려하기 위한 경진 대회가 개최되고 있다.3-5) 국내에서는 2015년 현대자동차 그룹에서 제13회 미래 자동차 기술 공모전의 한 분야로서 자율주행 인식 기술 관련 영상 인식 경진 대회를 개최했다.
인식 기술의 성능은 기술 개발에 활용한 데이터세트에 의존하여 데이터세트에 포함되지 않은 도로 환경에 대해서는 인식 성능이 매우 낮아진다. 이러한 문제점은 실제 주행 환경에서 수집한 다양한 데이터를 활용하여 해결해야 한다. 하지만 자율주행 인식 기술 데이터를 획득하기 위한 장비를 개발하는 데 많은 돈과 시간이 소요되며, 데이터를 가공하는 데에도 많은 시행착오를 겪는다.
본 연구에서는 다양한 도로 환경을 반영한 센서 융합 데이터인 KODAS(Korea Dataset for Autonomous Solution) 데이터세트를 구축하였다. 또한, 자율주행 데이터의 획득 과정과 데이터의 가공을 설명하고, KODAS 데이터세트 기반의 자율주행 경진 대회와 그 결과를 분석하여 활용성을 검증하였다.
2. 자율주행 인식 기술을 위한 데이터세트 구축 현황
2.1 국외 데이터세트
최근 자율주행 기술 개발을 지원하기 위해 공개된 데이터세트는 Table 1과 같다. 대표적인 데이터세트로는 Karshule Institute의 KITTI 데이터세트, Baidu사의 apolloScape 데이터세트, Waymo사의 Waymo Open 데이터세트, Aptiv의 nuScenes 데이터세트, Argo Ai사의 Argoverse 데이터세트가 있다. 데이터세트들의 목적은 자율주행에 필요한 인식 기술 알고리즘의 개발과 성능 평가 지원을 통해 자율주행 기술 발전을 장려하는 것이다. 각 데이터세트는 자율주행 기술 중에서도 가장 기본이 되는 주변 환경 검출(Detection) 분야를 공통적으로 지원하며, 데이터세트 목적에 따라 이미지 분할(Segmentation), 차량 측위(Localization), 이동 차량 추적(Tracking) 등을 지원한다. 또한, 인식된 결과를 온라인상에 공개함으로써 알고리즘 개발 활성화에 기여하고 있다.

International automated vehicle recognition dataset and its target applications6-15)
Domestic automated vehicle recognition dataset and its target applications16-18)
각 데이터세트의 인식 기술 분야에서 주변 환경 검출에 대한 상세한 데이터 구성은 Table 3과 같다. 각 데이터세트들은 배포되는 데이터의 형태 및 용량, 물체 클래스 수, 학습(Training)/평가(Test) 데이터 비율이 다르다. 또한, 목적에 따라 추가적인 속성 정보(Attribute)를 제공하고 있다. 자율주행 인식 기술 데이터들은 카메라 영상과 라이다 데이터 등 같은 시점에 획득된 센서 데이터들이 한 프레임을 구성한다. 데이터세트들의 데이터 제공 방식으로는 임의의 한 프레임과 스트리밍(Streaming)으로 제공하는 방식으로 나뉜다. 임의의 프레임 제공 방식은 주변 환경 인식 기술 개발에 주로 활용되며, 실용적인 알고리즘 개발을 위해서는 다양한 환경의 프레임을 구성하는 것이 적합하다. 스트리밍으로 제공하는 방식은 차량과 보행자 등 물체를 추적하는 알고리즘 개발에 유용하다. 데이터 용량은 데이터를 저장하는 시간 간격, 이미지 데이터 저장 속도, 이미지 크기, 센서 개수 등의 요인에 의해서 달라진다. 획득된 센서 데이터들은 데이터세트의 목적에 따라서 다르게 가공된다. KITTI의 경우 영상 처리 기반의 데이터 활용을 위해 가공된 데이터이며, ApolloScape는 환경 인식을 위한 데이터, nuScenes는 환경 데이터, Waymo Open은 주변 환경 검출을 위한 데이터, Argoverse는 맵과 주변 차량과의 운행 분석을 위한 데이터로 구성되어 있다.
The comparison of object detection on automated vehicle dataset (F: front, S: side, B: back, L: left, M: middle, R: right)
2.2 국내와 KODAS 데이터세트
국내에서 자율주행 기술 개발을 위해 공개된 데이터는 Table 2와 같다. 네이버와 국토지리정보원은 자율주행을 위한 정밀 도로지도를 제공하며 차량의 측위를 지원한다. 한국과학기술원에서 구축한 데이터세트는 인식 기술을 지원하기 위한 데이터로 다중센서 데이터와 기준 정보를 제공한다. 또한, 주변 인식이 어려운 야간 환경에서의 컬러(RGB) 영상과 열화상 영상 및 융합한 데이터를 제공한다. 하지만 대부분의 데이터가 학교 교내에서만 수집되었다는 한계점이 있다. 본 연구에서는 국내 다양한 도로 환경을 반영한 KODAS 데이터세트를 구축하였다. KODAS 데이터는 국내 도로 환경에 대한 데이터로 자체적으로 개발한 데이터 획득 시스템을 이용하여 취득한 위험 상황(Critical situation) 데이터, 이동체 데이터, 고정 환경 데이터로 구성되어 있다.
본 연구에서는 자율주행 인식 기술용 데이터 획득을 위한 기준 자동차를 개발하였다. 획득되는 데이터의 신뢰성 측면에서 센서들의 정확한 보정 값(Calibration parameter)과 동기화(Syncronization)를 하는 것이 중요하며, 획득한 데이터를 가공하여 속성정보와 실측값(Ground truth)을 입력하는 과정이 필요하다, 또한, 데이터 활성화를 위해 사용자에게 표준화된 포맷을 제공하였고, 데이터의 접근성을 높이기 위해 데이터 검색을 통하여 다운로드가 가능하도록 하였다.
기준 자동차는 다양한 데이터 획득을 위한 다중센서가 장착되어, 움직이는 물체 데이터를 실시간으로 취득할 수 있는 데이터 수집용 차량이다. 센서 데이터를 저장하는 장치는 중앙집중식 시스템과 분산식 시스템이 있다. 첫 번째, 중앙집중식 시스템은 단일 PC만을 사용하므로 데이터 동기화 부분이 유리하지만, 센서 개수를 확장하는 데 어려움이 있다. 두 번째 분산식 시스템은 센서별 시스템이 여러 대로 구성되므로 시스템 확장에 적합하지만 데이터 동기화를 하는 데 높은 기술력이 요구된다. 본 연구에서는 차후 센서 확장을 위하여 분산식 시스템으로 구성하였다. 각각의 시스템에 EtherCAT 장치를 활용하여 동기화 시스템을 구축하였다. 이를 통하여 주기적인 GPS/INS 정보를 각각의 센서 저장 시스템으로 전달하여 모든 센서 프레임 데이터에 저장된 시간과 위칫값들을 포함하게 했다.
Fig. 1은 본 연구에서 구축한 기준 자동차와 탑재 센서를 보여준다. 차량의 탑재 센서는 환경 인식 센서 5종 16개와 위치 인식 센서 3종 4개로 구성하였다. 환경 인식 센서는 라이다(Lidar) 센서 5대, 레이더(Radar) 센서 3대, 영상 카메라 센서 6대, 온/습도 센서 1대, 조도 센서 1대이며, 위치 인식 센서는 INS/DGPS, DMI, OBD-II이다. 전체적인 시스템 동기화를 위하여 주 PC와 여러 보조 PC 간 인터페이스는 EtherCAT 통신을 포함한다. Fig. 1은 각각의 로깅된 센서들의 저장된 시간을 보여준다. 차량에 탑재한 카메라의 보정 값과 라이다와 카메라 센서의 보정 값, 라이다-INS 보정 값 등을 추출하였고,19,20) 관련 보정 값을 KODAS 데이터세트에 포함하였다.

The data acquisition vehicle
본 연구에서는 국내 다양한 환경에서 획득한 데이터로 데이터세트를 구축하였다. 각각 대용량 데이터는 2분 단위로 저장하였다. 데이터의 속성 정보는 획득 위치, 측정 거리/평균속도, 측정시간, 기상(주간, 야간), 일광(맑음, 흐림, 비, 눈), 신호등(유, 무), 도로 유형(고속화 도로, 시내 도로, 캠퍼스, 골목), 복잡도(한적, 보통, 복잡)를 포함한다. 획득된 데이터는 자율주행 자동차에 탑재된 단일 센서로는 인식하기 어려운 환경이 존재함을 드러낸다.
KODAS 데이터세트에 포함된 단일 센서로 인식하기 어려운 상황을 Fig. 2가 보여준다. Fig. 2(a)는 빛번짐 상황으로 영상 기반 접근 방식으로는 주변 차량을 검출하기 어렵다. Fig. 2(b)의 비가 오는 환경과 Fig. 2(c)의 야간 환경도 영상으로 주변 차량을 검출하기 어려운 상황이다. Fig. 2(d)는 차량 와이퍼가 움직여서 물체 일부만 데이터로 획득된 상황이다. 이러한 상황들은 단일 센서만으로 인식하는 데 한계가 있기 때문에 다중센서 융합을 통해 극복해야 한다.

The critical scene images on the driving road in part 1
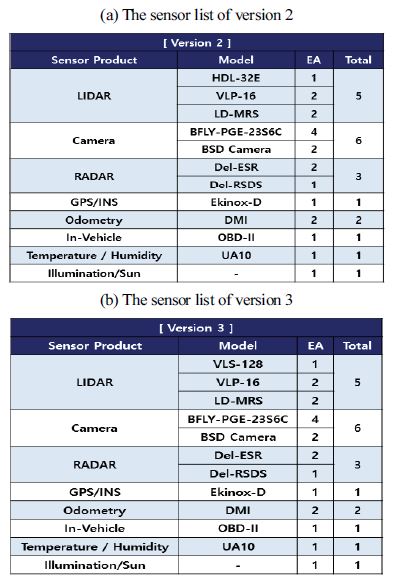
KODAS 데이터세트는 2015년부터 초기 구축을 시작하여 센서 종류, 수집 환경, 데이터 품질에 따라 버전 1부터 3까지 구축하였고, 현재 버전 2와 3을 공개하였다. Table 4는 KODAS 데이터세트 버전 2와 3을 구축하기 위하여 기준 자동차에 장착된 센서 목록을 보여준다. 버전 2와 3의 센서 시스템의 큰 차이는 라이다 센서의 성능이다. 버전 2의 데이터세트는 32채널 라이다 센서로 획득한 데이터를 포함하고 있으며, 버전 3의 데이터세트는 128채널 라이다 센서로 획득한 데이터를 포함하고 있다. 32채널 라이다 센서는 100 m까지 측정이 가능하지만 실측값의 유효거리는 최대 60 m인 반면 128채널의 라이다 센서는 300 m까지 측정이 가능하고 실측값의 유효 거리는 약 100 m까지이다.
The multiple sensor on the data acquisition vehicle
라이다 센서는 주변 환경 정보를 획득하기 위한 주 센서이며, 다중센서 융합 결과에 큰 영향을 준다.
본 데이터세트를 설계하고 구성하기 위해 2017년도부터 현재까지 매년 자동차공학회의 전문 연구 세션을 통하여 데이터 구축 상황을 공유하고, 전문가 의견을 반영하였다. 또한, 구축된 데이터세트에 대한 신뢰성을 확보하기 위해 한국산업기술시험원에 의뢰하여, 벡터 지도의 실측값 정밀도, 영상센서 실측값의 정밀도, 거리센서 실측값의 정밀도, 확장형 지도를 위한 항공 영상의 정밀도에 대한 평가를 받았다.
3. 자율주행 인식 기술 경진 대회
기준 정보 데이터(Ground Truth: GT)는 객체의 실측값 데이터로서 대회용 데이터세트의 핵심 구성 요소이다. 영상이나 거리 데이터의 GT는 두 가지 방법으로 제공할 수 있다. 객체를 포함하는 박스 형태의 실측 정보를 제공하는 방법과 최대한 객체들의 외곽에 맞도록 실측 정보를 제공하는 방법이 있다. 전자의 경우 검출이나 추적에 주로 활용되고, 후자의 경우 이미지 분할이나 분류에 활용된다. 이번 자율주행 인식기술 경진대회에서는 객체의 검출에 중점을 두고 있기 때문에 박스 형태의 레이블링 된 정보를 GT로 제공한다. 거리 데이터는 BEV(Bird Eye View) 기준으로 레이블링한다.
영상 데이터의 경우, 겹쳐 있는 객체들은 각각 따로 레이블링을 하고, 육안으로 확인하기 어려운 객체들을 제거하기 위해 30픽셀 이상의 객체들만 레이블링하였으며, 인도가 아닌 도로 위 주차 공간에 주차된 이동객체들만 레이블링하는 등 명확한 기준에 근거하여 GT 정보를 생성하였다. 마찬가지로 거리 데이터의 경우에도 3차원 라이다 점군으로부터 직육면체로 레이블링한 후 2차원으로 정사영하고, 80 m 이내에 존재하고 50개 이상의 점군을 포함한 객체들만 분리하는 등 사전에 정의된 레이블링 기준에 따라 GT를 생성하였다.21) 또한, 영상 및 거리 데이터 간에 각 객체의 ID를 매칭하여 다중센서 융합 연구에 사용할 수 있도록 하였다.
3.1 자율주행 인식 기술 경진 대회 분야
대회는 두 가지 분야로 나누어 진행하였다. 첫 번째는 전방(Front looking) 영상 기반의 융복합 인식 기술 분야, 두 번째는 전 방향(Onmi-directional) 거리 기반의 융복합 인식 기술 분야로 분류하여 개최하였다. 첫 번째 전방 영상기반의 융복합 인식 기술 분야는 차량의 전방 카메라, 전방의 32채널 라이다 데이터를 제공하여 전방의 차량과 보행자를 인식할 수 있도록 제공하였다. 두 번째 전 방향 거리 기반의 융복합 인식 기술 분야는 전후방의 카메라와 전 방향의 128채널 라이다 데이터를 제공하여 전 방향의 차량과 보행자를 인식할 수 있도록 하였다. KODAS 데이터는 39개의 클래스를 가지고 있지만, 경진 대회 참가자의 확대와 난이도를 고려하여 3개의 클래스로만 간소화하여 제공하였다. 경진 대회는 국내의 자율주행 인식 기술을 연구하는 모든 사람이 참여할 수 있도록 하였다.
Fig. 3은 경진 대회 첫 번째와 두 번째 분야 참가자에게 제공했던 데이터 종류를 보여준다. 분야별 학습과 평가 데이터를 각각 제공하였으며 학습 데이터에는 GT 데이터가 포함되어 있다. Fig. 4는 평가 프로세스를 보여주며, Fig. 5는 첫 번째와 두 번째 분야에 제공된 데이터와 제공된 데이터 기반으로 참가자들이 인식한 결과의 일부를 보여준다. Fig. 4에 나타나 있듯이 참가자가 인식 결과를 제출하면 GT 정보와의 비교를 통해 mAP(mean Average Precision) 결과를 도출하였다.

The dataset structure of part 1 and part 2

The evaluation overview of recognition

The examples of test data and the reorganization results for KODAS challenge part 1 and 2
Fig. 6(a)는 경진 대회 첫 번째 데이터의 기준 자동차와 인식해야 하는 객체(보행자와 차량)의 거리 분포를 나타내며, Fig. 6(b)는 두 번째 데이터의 기준 자동차와 객체 간 거리 분포를 나타낸다. 그래프의 x축은 기준 자동차와 객체 간의 거리를 나타내며, y축은 객체 개수를 나타낸다. Fig. 6(a)와 같이 첫 번째 데이터에서는 32채널 라이다 센서의 유효 거리로 인해 객체의 대부분이 기준 자동차로부터 20∼40 m에 분포하고 있으며, 40 m 이후 객체 수가 급격히 떨어진다. 경진대회에서는 정확한 GT를 제공하기 위해 필요 이상으로 작은 픽셀의 객체는 제한하였다. Fig. 6(b)를 보면 128채널 라이다 센서를 사용하는 두 번째 분야의 데이터에서는 기준 자동차로부터 70 m까지도 상당히 많은 객체가 분포하는 것을 알 수 있다. 두 번째 분야에서는 정확한 GT 정보를 제공하기 위하여 70 m 이내의 물체만 인식할 수 있도록 실측 정보를 제한하였다. 데이터 분포에서 나타나듯이 라이다 센서의 채널 수가 많아질수록 원거리 물체까지 검출할 수 있으므로 더욱 많은 실측 정보를 확보할 수 있다. 경진대회 데이터에 대한 추가적 데이터 분포는 Fig. 9부터 Fig. 12까지와 같다. Fig. 9는 첫 번째 데이터의 이미지별 레이블의 개수를 보여주며, Fig. 10은 첫 번째 데이터를 획득할 때의 환경(맑음, 비, 어스름, 야간) 분포를 보여주고, Fig. 11은 첫 번째 데이터의 다양한 도로 분류를 보여준다. Fig. 12는 두 번째 데이터의 프레임별 레이블 개수를 보여주고 있다.

Statistics of object distances of the dataset for KODAS challenge part 1 and 2
3.2 자율주행 경진 대회 평가 결과
자율주행 인식 기술 경진 대회 날 연구 발표회를 통하여 KODAS 데이터세트 설명 및 참가자들의 인식 결과, 연구 방법을 공유하였다. 각 분야에서는 정확도와 재현율(Precision-Recall) 곡선 기반의 mAP를 통하여 결과를 비교 분석하였다. 차량과 보행자의 크기가 다르므로 IoU(Intersection of Union)의 중첩도 값을 상이하게 설정하였다. 차량의 경우 IOU를 0.5로 설정한 반면 보행자의 경우에는 0.33으로 설정하였다. Fig. 7은 참가팀의 인식 결과에 대한 정확도와 재현율을 보여주고 있다. Fig. 7(a)를 보면 Recall의 후반부로 갈수록 인식률은 감소하지만 전체적인 mAP는 상승하고 있다. Fig. 7(b)의 경우에는 인식률 자체는 높아서 인식기의 성능은 매우 우수하지만 mAP에 대한 한계가 있는 결과가 도출되었다. 이처럼 인식 성능에 대한 확신도가 높으나 인식률이 높지 않은 팀이 있는 반면 인식 성능에 대한 확신도가 낮으나 전체적으로 인식률이 높은 팀이 있었다. 그리고 영상처리의 단점을 보완하기 위해 본 데이터세트에 다양한 센서 데이터를 융합하는 인식기를 설계한 팀도 있었다. Fig. 8에 보이듯이 이미지 자체만으로는 객체를 인식하기 어려운 환경에서 이미지 처리만을 통하여 객체 인식을 시도한 팀과 융합 데이터 인식기를 개발하여 이를 극복하려 한 팀이 있었다.

The sample results of recognition evaluation

The result of recognition with non-fusion and fusion algorithm

Number of objects per class and image for KODAS challenge part 1. This figure shows how many objects per class are in the image. The challenge dataset was composed of three classes(car, person and etc) to clarify and simplify the evaluation of the challenge. Note that etc class represents the rest of the objects except cars and persons

Number of objects per class according to weather and daylight. As shown in the figure, the KODAS dataset reflects a challenging environment in which object recognition is difficult

Number of objects per class according to road environments such as highway, city road, alleyway

Number of objects per class and frame for KODAS challenge part 2. This figure shows how many objects per class are in the frame. Note that each frame contains the omnidirectional objects annotated based on 128 channel Lidar
4. 결 론
본 논문에서는 자율주행 인식 기술 개발을 위한 KODAS 데이터세트를 소개하고, KODAS 데이터 수집 및 가공 과정에 대해 설명하였다. KODAS 구축 시스템은 라이다 센서 5개, 레이더 센서 3개, 카메라 6개, GPS/INS 등 총 20개의 센서들로 구성되어 있고, 각각의 센서들에 대한 보정 정보(Calibration)를 제공한다. KODAS는 크게 이동체 데이터와 고정 환경 데이터로 나뉘고, 자율주행 인식 기술의 완성도를 높이기 위해 필요한 위험 환경(Critical case) 데이터를 다수 획득하였다. 또한, 학습 데이터와 평가용 데이터를 각각 구축하였다.
이와 같이, 본 논문에서는 자율주행 인식 기술 개발을 위한 KODAS 데이터세트를 구축하고, 경진 대회를 통해 KODAS의 활용성을 검증하였다. 경진 대회에서는 주간, 야간, 강우, 도심, 고속도로 등 다양한 환경의 데이터를 참가팀에 제공하고, 인식 기술 평가시스템을 통해 각 참가팀이 제출한 인식 결과를 평가하였다. 이번 경진 대회에서는 이동체 인식 분야에 집중되어 있었지만, 향후에는 고정 환경 인식 및 이를 활용한 자차 측위, 맵 생성/갱신 분야도 추가할 예정이다. 또한, 구축한 KODAS 데이터세트는 경진 대회를 통해서 발견된 문제점들을 보완하고 품질을 향상시켜 모든 연구자들이 활용할 수 있도록 공개할 계획이다.
References
-
M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn and A. Zisserman, “The PASCAL Visual Object Classes Challenge: A Retrospective,” International Journal of Computer Vision, Vol.111, No.1, pp.98-136, 2015.
[https://doi.org/10.1007/s11263-014-0733-5]

-
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision, Vol.115, No.3, pp.211-252, 2015.
[https://doi.org/10.1007/s11263-015-0816-y]
- Common Object in Context(COCO), ICCV 2019 Joint COCO and Mapillary Recognition Challenge, http://cocodataset.org/workshop/coco-mapillary-iccv-2019.html, , 2019.
- UNC Vision Lab, Large Scale Visual Recognition Challenge 2017, http://image-net.org/challenges/LSVRC/2017, /, 2019.
- Megvii, Detection In the Wild Challenge Workshop 2019, http://www.objects365.org/workshop2019.html, , 2019.
- Karshule Institute, The KITTI Vision Benchmark Suite, http://www.cvlibs.net/datasets/kitti/, , 2012.
- Baidu, APOLLOSCAPE Dataset, http://apolloscape.auto, , 2019.
- Aptiv, NUSCENES Dataset, https://www.nuscenes.org, /, 2019.
- Waymo, Waymo Open Dataset, https://waymo.com/open/, , 2019.
- Argo Ai, Argoverse Dataset, https://www.argoverse.org/index.html, , 2019.
-
A. Geiger, P. Lenz, C. Stiller and R. Urtasun, “Vision Meets Robotics: The KITTI Dataset,” The International Journal of Robotics Research, Vol.32, No.11, pp.1231-1237, 2013.
[https://doi.org/10.1177/0278364913491297]
-
Y. Ma, X. Zhu, S. Zhang, R. Yang, W. Wang and D. Manocha, “Trafficpredict: Trajectory Prediction for Heterogeneous Traffic- agents,” Proceedings of the AAAI Conference on Artificial Intelligence, Vol.33, pp.6120-6127, 2019.
[https://doi.org/10.1609/aaai.v33i01.33016120]
-
H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishanan, Y. Pan, G. Baldan and O. Bejibom, “nuScenes: A Multimodal Dataset for Autonomous Driving,” arXiv preprint arXiv:1903.11027, , 2019.
[https://doi.org/10.1109/CVPR42600.2020.01164]
-
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens, Z. Chen and D. Anguelov, “Scalability in Perception for Autonomous Driving: An Open Dataset Benchmark,” arXiv preprint arXiv:1912.04838, , 2019.
[https://doi.org/10.1109/CVPR42600.2020.00252]
-
M. F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Rammanan and J. Hays, “Argoverse: 3D Tracking and Forecasting with Rich Maps,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.8748-8757, 2019.
[https://doi.org/10.1109/CVPR.2019.00895]
-
Y. Choi, N. Kim, S. Hwang, K. Park, J. S. Yoon, K. An and I. S. Kweon, “KAIST Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving,” IEEE Transactions on Intelligent Transportation Systems, Vol.19, No.3, pp.934-948, 2018.
[https://doi.org/10.1109/TITS.2018.2791533]
- NAVER Labs, NAVER Labs HD Map Dataset, https://hdmap.naverlabs.com, , 2019.
- National Geographic Information Institute, High Definition Map, http://map.ngii.go.kr/ms/pblictn/preciseRoadMap.do, , 2019.
- B. Hong, S. Baeg and S. Park, “An Extrinsic Calibration Method for Vehicle Equipped LiDARs and INS Sensor,” KSAE Annual Conference Proceedings, pp.732-733, 2018.
- K. Cho, S. I. Ham and S. G. Kang, “Introduction of Standard Open DB for Intelligent Vehicle Awareness Technology Support,” KSAE Annual Conference Proceedings, pp.1397-1398, 2018.
-
S. C. Kee, “A Study on the Image DB Construction for the Multi-function Front Looking Camera System Development,” Transactions of KSAE, Vol.25, No.2, pp.219-226, 2017.
[https://doi.org/10.7467/KSAE.2017.25.2.219]